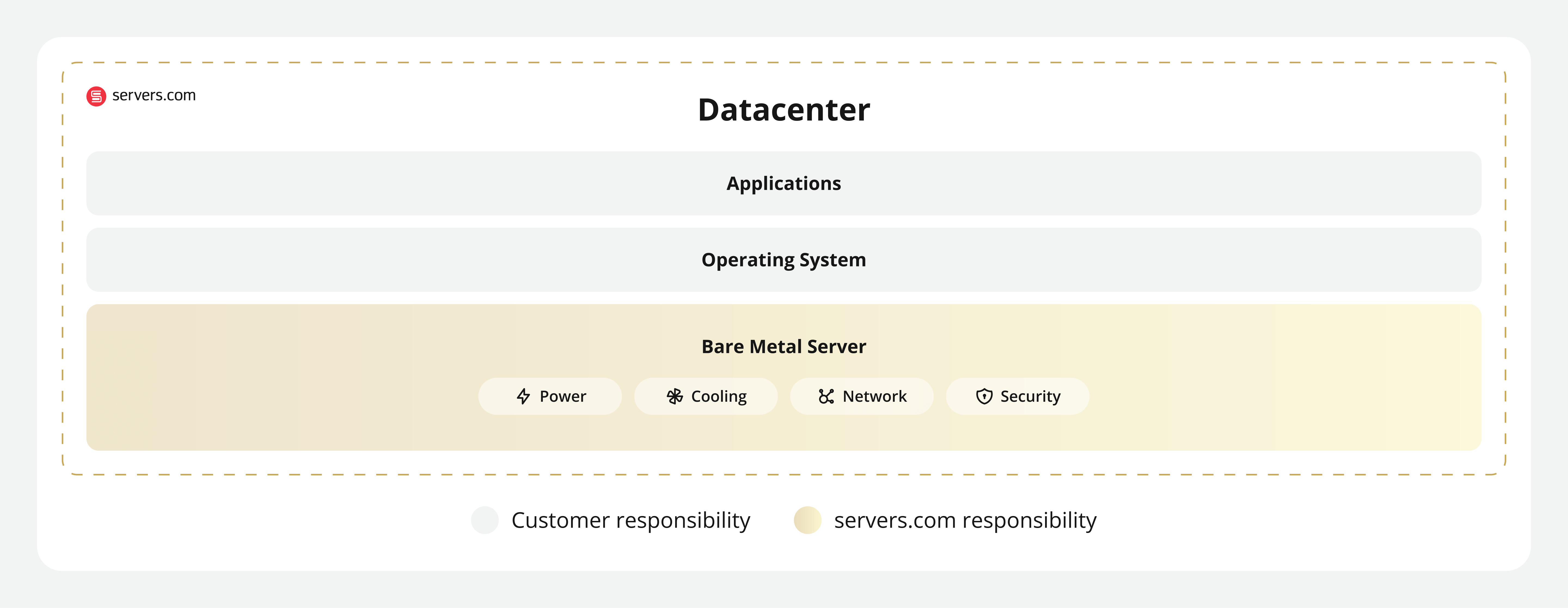
As streaming platforms mature, the demands on your infrastructure shift beyond rapidly scaled delivery and into a state of sustained processing. Encoding and transcoding are only part of that picture. At this stage, packaging workflows, DRM operations, metadata enrichment, format generation, thumbnail processing, AI enhancement, and analytics ingestion are all operating as continuous data pipelines.
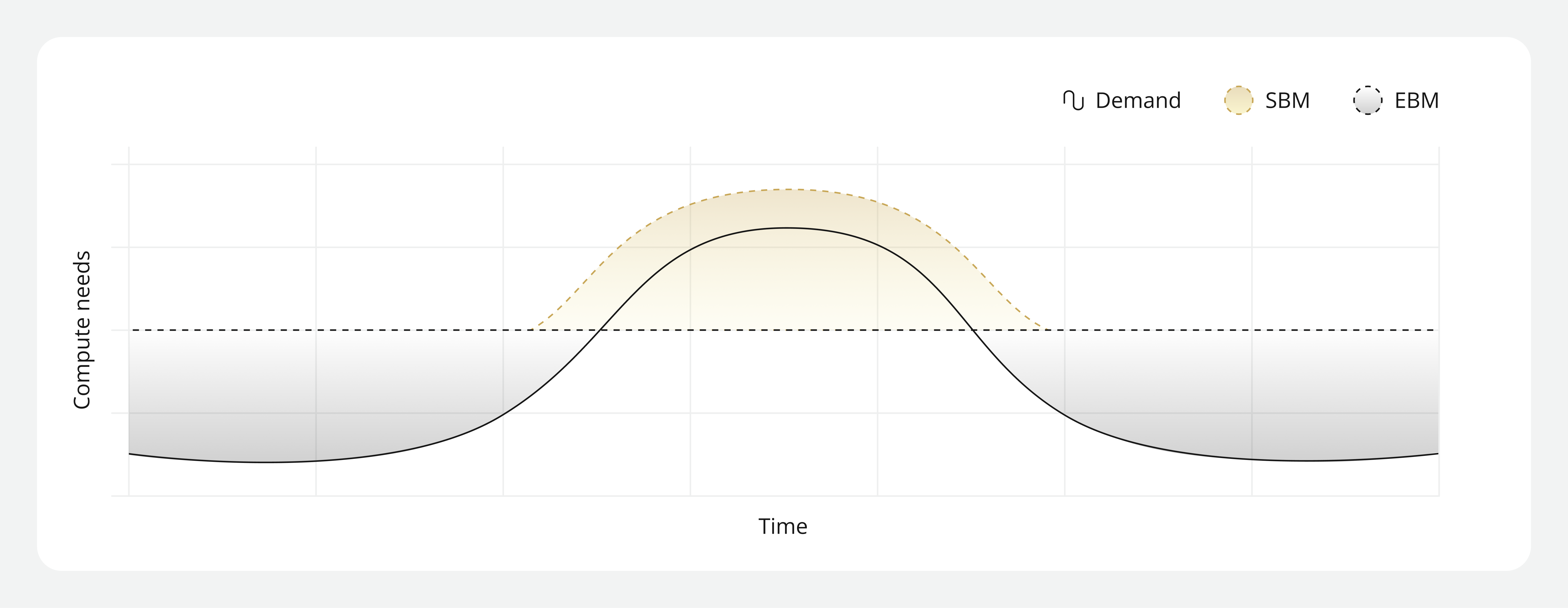
And unlike audience traffic, which rises and falls with demand fluctuations, these compute-heavy workflows run persistently in the background. Over time, they establish a stable baseline demand that shapes both cost behavior and performance expectations.
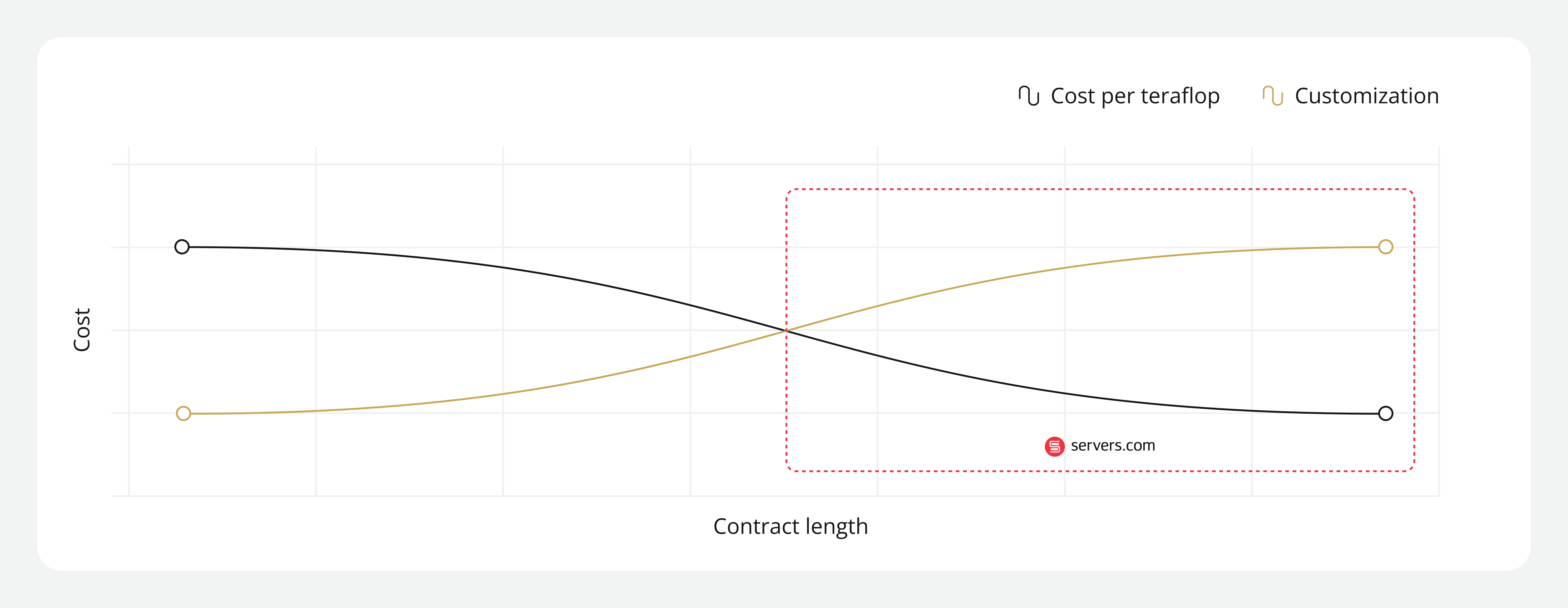
Highly elastic streaming compute infrastructure excels at responding to audience traffic variability. But sustained streaming pipelines require highly optimized infrastructure architectures built for consistent throughput, predictable CPU allocation, and stable execution under continuous load. So, when choosing the best compute type for these types of workloads, the question needs to shift from “what will help us scale quickly?” to “what will help us stabilize compute behavior and optimize cost for workloads that rarely power down?”
Where always-on pipelines break down
Always-on streaming pipelines tend to break down when they’re placed on streaming compute infrastructure built for burst patterns rather than infrastructure built for sustained, stable, and deterministic performance. When workloads aren’t placed on suitable infrastructure it results in unpredictable cost volatility and increased performance ambiguity.
1. Cost volatility
Highly elastic, virtualized environments make sense for workloads with spiky demand patterns. But for persistent workloads these environments become difficult to manage, resulting in accumulated egress and compute charges, and blurred unit economics. As a result, finance teams struggle to model baseline cost and engineering teams to explain why.
2. Performance ambiguity
When throughput drops in virtualized public cloud environments, it can be difficult to isolate the route cause because you don’t have control over the underlying hardware. It could be down to a contention issue, codec misconfiguration, or even CPU performance variability.
Without deterministic compute, infrastructure variance becomes indistinguishable from application variance, making optimization (and diagnostics) much harder. And for streaming businesses delivering services at scale, this obfuscation is a commercial risk.
Performance variability was one of the challenges video processing platform, Ceeblue, experienced while scaling high-throughput transcoding workflows. By working closely with servers.com to tune their infrastructure at the hardware level, Ceeblue was able to improve streaming performance and optimize encoding throughput.
“servers.com provides us with the latest and greatest in hardware, and we know the difference between hardware that just works well enough and hardware that offers exceptional performance,” said Danny Burns, Founder and CTO at Ceeblue.